Why pilots fail to scale
Most enterprise AI initiatives stall at the pilot stage. The gap between a successful proof-of-concept and a production-ready system is often wider than leadership expects. This failure rarely stems from a lack of algorithmic accuracy. Instead, it results from infrastructure gaps and a lack of governance that become apparent only when data volume and user load increase.
The problem is structural. Pilots are typically built in isolated environments with clean, small datasets. Production requires integration with legacy systems, real-time data streams, and strict security protocols. Without a unified architecture, models that perform well in testing degrade quickly under real-world conditions. This is why so many initiatives never move beyond the experimental phase.
85% of AI pilots fail to move to production, according to industry analyses from Scaled Agile and Deloitte.
To escape this trap, organizations must treat AI adoption as an engineering challenge, not just a data science project. This means investing in robust MLOps pipelines, establishing clear data governance frameworks, and ensuring that infrastructure can support the computational demands of large language models. The cost of fixing these issues in production is exponentially higher than addressing them during the pilot phase.
Map your enterprise infrastructure
Before scaling an AI initiative, you must align your technical foundation with the demands of production-grade workloads. This isn't just about buying more compute; it's about ensuring your data pipelines are robust enough to feed models reliably and your security posture can handle sensitive enterprise data. Without this groundwork, pilots stall in the "valley of death" between proof-of-concept and actual business value.
Start by auditing your existing data architecture. OpenAI’s enterprise guidance emphasizes that successful adoption often requires customizing and training models on proprietary data, which means your data needs to be clean, accessible, and governed. If your data is siloed in legacy systems or lacks proper metadata, model accuracy will suffer regardless of the algorithm used. Map out where your critical data lives, how it moves, and who has access to it. This inventory becomes the blueprint for your integration strategy.
Next, prioritize security and compliance. The Cloud Security Alliance notes that defining clear objectives and leveraging external expertise early can prevent costly rework. Ensure your infrastructure supports role-based access control (RBAC), encryption at rest and in transit, and audit logging. These aren't optional features; they are prerequisites for any enterprise AI deployment that handles customer or financial data.
Investing in this infrastructure map pays dividends later. It reduces integration friction, accelerates time-to-value, and mitigates risk. Think of it as laying the tracks before the train arrives; you can't control the speed of the engine, but you can ensure the rails are solid.

The cost of building this infrastructure is significant, reflecting the broader trend of enterprise investment in AI capabilities. Understanding the market context helps justify these upfront capital expenditures to stakeholders.
Select the right enterprise tools
Choosing the right infrastructure is the difference between a pilot that stays in the sandbox and a production system that scales. You need tools that handle security, latency, and observability without forcing your engineering team to build custom glue code for every new model.
We recommend evaluating tools across three distinct layers of the stack. The LLM provider layer handles the core inference, orchestration manages the workflow logic, and monitoring ensures you can debug issues before they impact users.

LLM Providers and Orchestration
For most enterprises, starting with a managed provider like OpenAI or Anthropic reduces operational overhead significantly. OpenAI's enterprise guide emphasizes that their API offers the most mature guardrails for production deployments, including structured outputs and strict data privacy controls. Anthropic focuses heavily on constitutional AI and interpretability, which is critical for regulated industries.
However, relying on a single provider creates vendor lock-in. To mitigate this, use an orchestration layer like LangChain or LlamaIndex. These frameworks allow you to swap underlying models without rewriting your entire application logic. They also provide standardized interfaces for retrieval-augmented generation (RAG), which is essential for grounding AI responses in your proprietary data.
Monitoring and Observability
You cannot improve what you cannot measure. Traditional APM tools often miss the nuances of LLM interactions, such as token usage drift or hallucination rates. Specialized observability platforms like LangSmith or Arize Phoenix provide trace-level visibility into every step of the AI pipeline.
These tools help you identify bottlenecks in your RAG pipelines and track cost-per-token in real-time. Without this visibility, you risk uncontrolled spending and inconsistent user experiences.
Comparison of Top Enterprise AI Tools
The table below compares leading tools based on security, scalability, and integration ease. These factors should drive your selection process.
| Tool | Category | Security Focus | Scalability | Integration Ease |
|---|---|---|---|---|
| OpenAI API | LLM Provider | SOC 2, HIPAA, Data Privacy | High | High |
| Anthropic Claude | LLM Provider | Constitutional AI, Audit Trails | High | Medium |
| LangChain | Orchestration | N/A (Framework) | Medium | High |
| LangSmith | Observability | Enterprise SSO, Data Isolation | High | High |
| AWS Bedrock | LLM Provider | AWS Native, VPC Support | Very High | High |
Essential Infrastructure Components
To get from pilot to production, you need specific tools to handle the workload. These are not optional extras; they are the foundation of a stable enterprise AI system.



As an Amazon Associate, we may earn from qualifying purchases.
Start with a clear definition of your success metrics. Are you optimizing for latency, accuracy, or cost? Your answer will determine which tools from the table above are the best fit for your specific use case.
Execute the phased rollout
Moving from a controlled pilot to full-scale production requires a structured approach that prioritizes stability and user adoption over speed. This phase transforms your initial success into a scalable operational reality. We will walk through the specific steps to ensure your enterprise AI integration is robust, secure, and widely accepted.
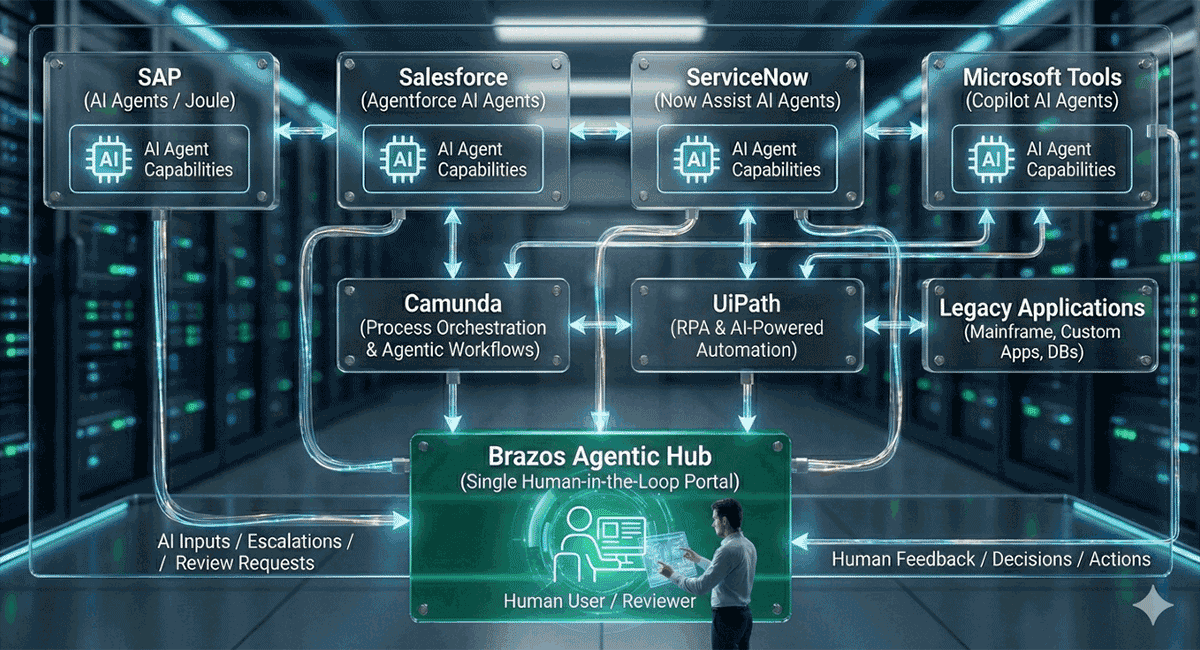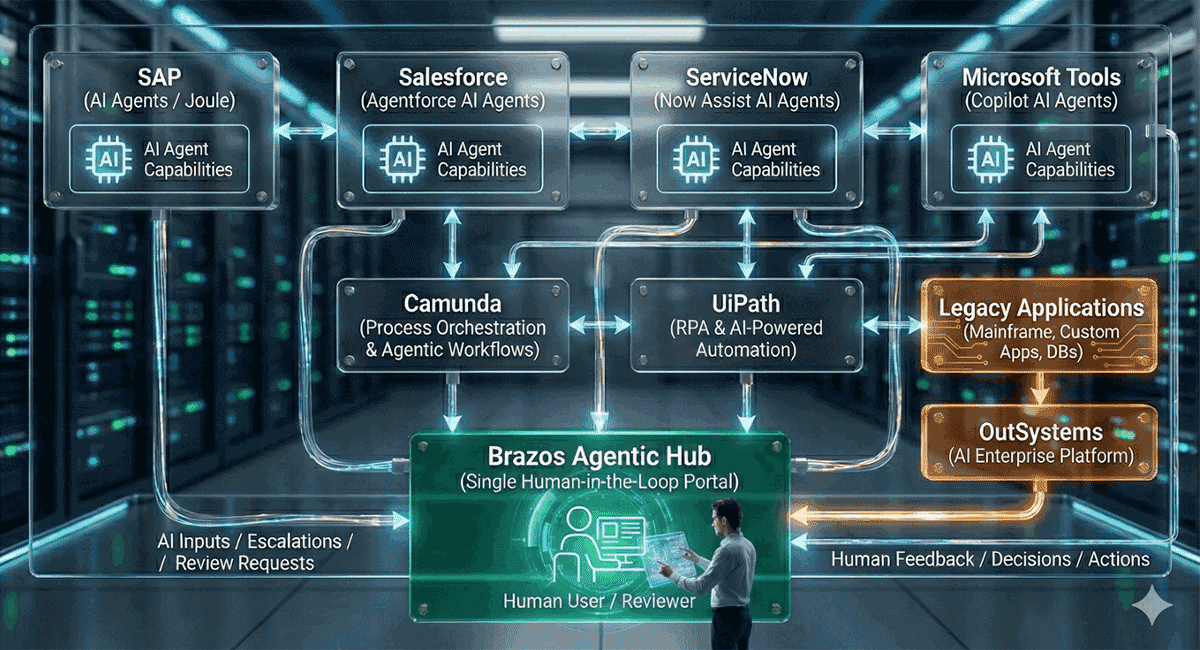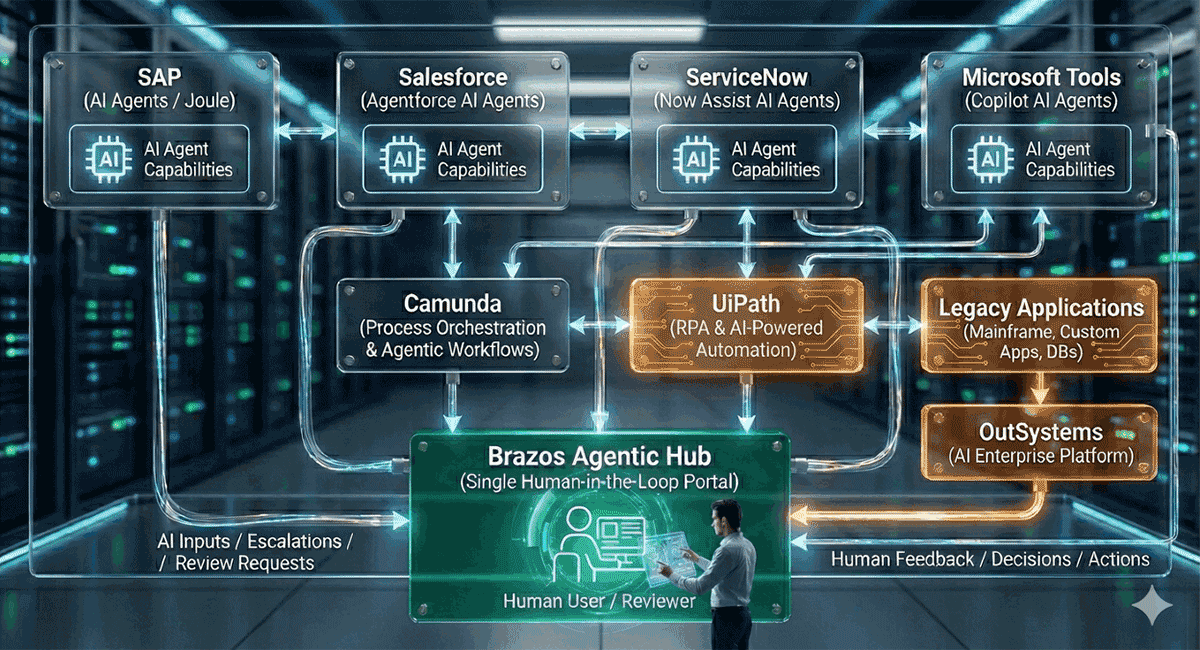
Before deploying code, deploy people. Successful enterprise AI adoption starts with clear communication and training. Identify early adopters and empower them as champions within their teams. These champions provide peer support, reducing resistance and creating a culture of curiosity rather than fear. Deloitte emphasizes that leadership must actively model AI usage to signal its importance to the rest of the organization.

Enterprise adoption demands rigorous security checks. Ensure your AI solutions comply with GDPR, HIPAA, or other relevant regulations depending on your industry. Implement strict access controls and data governance policies. This step is non-negotiable for maintaining trust and avoiding legal liabilities. Verify that all data handling meets your internal security standards before proceeding to broader deployment.

Select a small, representative group of users to test the solution in a real-world environment. This group should include diverse roles to uncover varied use cases and potential friction points. Monitor their interactions closely to gather qualitative feedback and quantitative metrics. This controlled environment allows you to refine the user experience without risking widespread disruption.
Use data from the pilot to identify bugs, usability issues, and performance bottlenecks. Engage directly with pilot users to understand their pain points and suggestions. Iterate on the solution based on this feedback, making necessary adjustments to the interface, functionality, or underlying models. This iterative process ensures the final product truly meets user needs and delivers value.

Once the pilot is validated, roll out the solution to the broader organization. Provide comprehensive training resources, including documentation, video tutorials, and live workshops. Establish a dedicated support channel to address user questions and issues promptly. Monitor adoption metrics closely to identify areas where additional support or training may be needed.

Enterprise AI adoption is not a one-time event but an ongoing process. Continuously monitor system performance, user engagement, and business impact. Use these insights to optimize the solution, add new features, and address emerging challenges. Regularly update training materials to reflect changes and best practices. This continuous improvement cycle ensures your AI initiatives remain relevant and effective.
Monitor and optimize performance
Measuring success post-deployment is the difference between a temporary pilot and a permanent business asset. You need to move beyond simple uptime checks and start tracking metrics that reflect actual business value. Without this visibility, you risk drifting into a state where the AI is running but not contributing to your bottom line.
Start by defining a clear set of KPIs aligned with your initial goals. If you launched for cost reduction, track compute spend per transaction. If it was for speed, measure mean time to resolution. Deloitte’s research on agentic AI adoption highlights that successful enterprises don’t just monitor technical stability; they continuously audit for drift in reasoning and output quality as models and data evolve.
To keep your strategy viable, establish a feedback loop that connects user interactions back to your model. This isn’t just about logging errors; it’s about capturing human corrections and satisfaction scores to retrain or fine-tune your system. Treat your AI infrastructure like a living engine—regularly check the gauges, adjust the fuel mix, and listen to the feedback to ensure it’s running efficiently.
No comments yet. Be the first to share your thoughts!