Map the infrastructure requirements
Building the foundation for enterprise AI adoption isn’t about buying the biggest servers; it’s about aligning your existing data center capabilities with the unique demands of AI workloads. Before you can run large language models or predictive analytics at scale, you need to audit three core pillars: network, storage, and computing resources. These components work together to ensure that data moves quickly, stays secure, and is processed efficiently.
Network Infrastructure
AI models require massive amounts of data to be moved between GPUs and storage systems in real-time. Standard enterprise networks often bottleneck this process, leading to idle compute time. You need high-bandwidth, low-latency connections that can handle the traffic spikes inherent in training and inference. This means upgrading switches, routers, and wireless access points to support the throughput required by modern AI chips. Without a robust network layer, even the most powerful computing resources will sit underutilized.
Storage Infrastructure
Data is the fuel for AI, and storage infrastructure must keep it safe and immediately accessible. Traditional hierarchical storage management is often too slow for AI training pipelines. You need high-performance storage solutions that can serve thousands of concurrent requests without dropping packets or slowing down. This includes evaluating whether your current data centers can handle the I/O intensity of AI workloads or if you need to implement tiered storage strategies that balance speed with cost.
Computing Resources
The heart of AI infrastructure is the compute layer. This goes beyond standard CPU-based servers. AI workloads rely heavily on GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units) to handle parallel processing tasks. You must assess whether your current cloud platforms and on-premise hardware can support these specialized chips. This often involves a shift from general-purpose computing to accelerated computing architectures, requiring careful planning around power, cooling, and physical space in your data centers.
Integrate compliance and security layers
Enterprise adoption stalls when legal and security teams view infrastructure as a liability rather than an enabler. To move from pilot to production, you must embed compliance and security controls directly into the deployment pipeline. This approach, often called "compliance by design," ensures that regulatory requirements are met at the code level before they ever reach the production environment.
The goal is to eliminate the "security tax" that usually slows down enterprise rollouts. By treating compliance as a technical constraint rather than a post-deployment audit, you reduce friction for IT administrators and build trust with stakeholders who need to see clear governance.

Start by translating high-level regulations like GDPR, HIPAA, or SOC 2 into specific technical configurations. Instead of vague policy statements, define exact encryption standards (e.g., AES-256), access control models (RBAC), and data retention periods. This creates a clear checklist for your engineering team to implement in the infrastructure code.
Integrate policy-as-code tools such as OPA (Open Policy Agent) or AWS Config Rules into your continuous integration and deployment workflows. These tools automatically scan infrastructure changes against your mapped requirements. If a deployment violates a security rule—such as opening a database port to the public internet—the pipeline blocks the change before it reaches production.

Move away from perimeter-based security by adopting a zero-trust model where every request is authenticated and authorized, regardless of its origin. Configure micro-segmentation to isolate critical workloads and enforce strict identity verification for all service-to-service communications. This minimizes the blast radius of potential breaches and satisfies rigorous enterprise security audits.
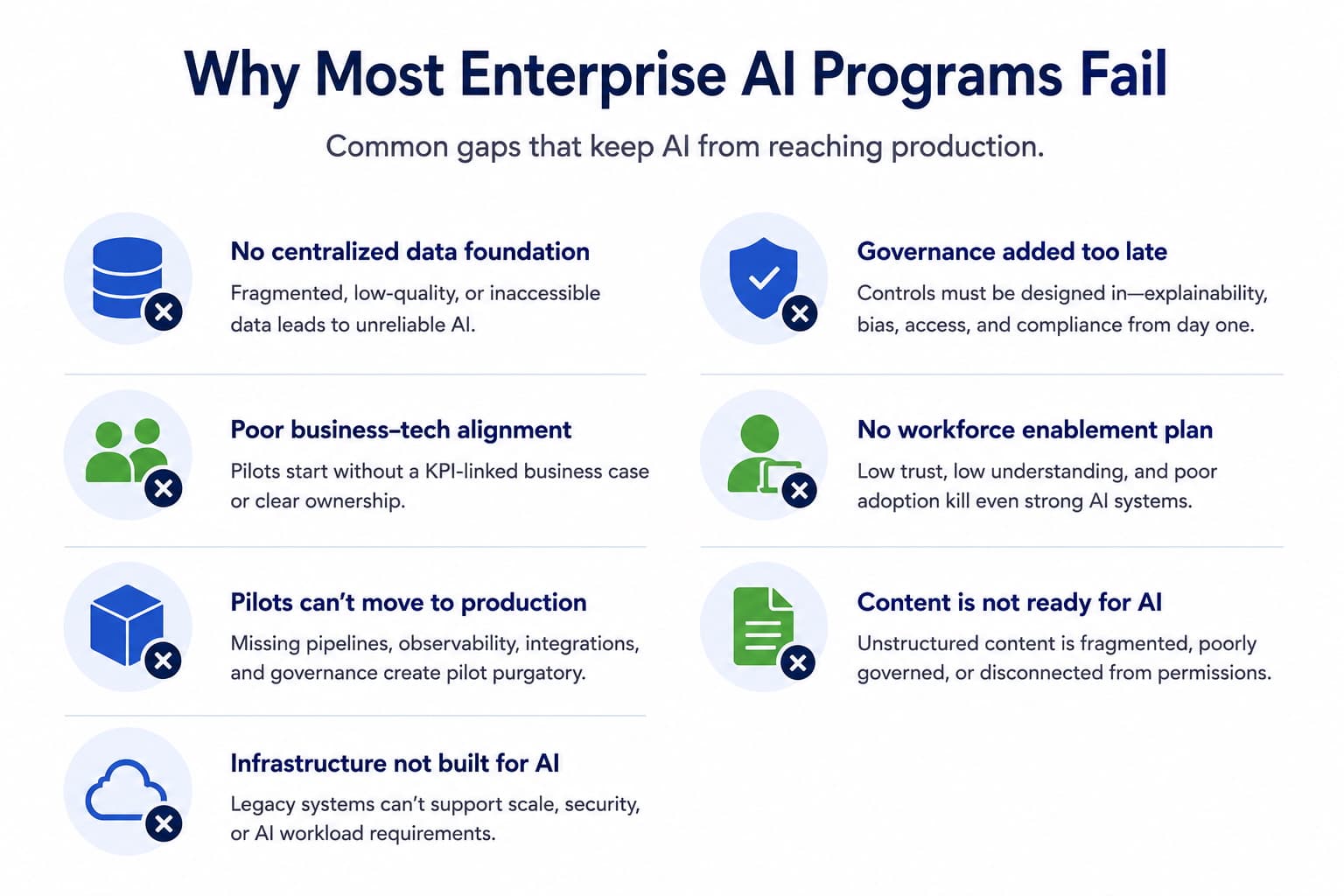
Deploy comprehensive logging and monitoring solutions that capture all access events, configuration changes, and data movements. Ensure these logs are immutable and stored in a secure, centralized location. Regular automated audits should verify that the infrastructure remains compliant with your defined policies, alerting teams to drift or anomalies in real-time.

As an Amazon Associate, we may earn from qualifying purchases.
Select the right enterprise tools
Treat this step as a welfare screen for Building Enterprise Adoption Infrastructure. Compare the source, the animal's visible condition, the seller's care knowledge, the paperwork, and the transport plan before you commit. A good purchase path should make the dragon's health easier to verify, not harder. Pause before paying if any part of the chain is unclear. Confirm the exact animal, pickup or shipping timing, heat-pack plan when relevant, return policy, and the supplies you need at home for the first week.
| Factor | What to check | Why it matters |
|---|---|---|
| Fit | Match the option to the primary use case. | A good deal still fails if it does not fit the job. |
| Condition | Verify age, wear, and service history. | Hidden condition issues erase upfront savings. |
| Cost | Compare purchase price with likely upkeep. | The cheapest option is not always the lowest-cost option. |
Validate with pilot tests
Nearly half of enterprises hit a wall when they try to scale AI, with 49% citing the difficulty of demonstrating value as their biggest barrier [src-serp-4]. A pilot test is how you clear that hurdle. Instead of betting the whole infrastructure on a broad rollout, you isolate a specific use case to prove the model works in your environment.
This phase is about stress-testing the connection between your data pipelines and the application layer. You need to verify that latency, throughput, and cost estimates hold up under real-world load. If the infrastructure chokes on production data volumes during the pilot, you fix it now rather than after deployment.
Before moving to full-scale deployment, run through this validation checklist to ensure the infrastructure is ready.
-
Define clear success metrics (e.g., latency < 200ms)
-
Verify data governance and privacy compliance
-
Test failover and recovery procedures
-
Measure actual compute costs against projections
The goal is to gather concrete evidence that the infrastructure delivers value. This data becomes your justification for the broader rollout, turning abstract technical specs into business outcomes that stakeholders can understand.
Frequently asked questions about enterprise infrastructure
Understanding the specific components and trends in enterprise adoption helps teams build infrastructure that actually supports business goals rather than just technical specs. Below are common questions about what makes up this infrastructure and how adoption is currently shifting.
No comments yet. Be the first to share your thoughts!